
使用 Python 处理 pdf
背景
最近老婆工作中碰到一些困难,总是跟我抱怨工作好烦,不开心。
主要是是因为要处理一些报告,这些 pdf 格式的样本报告比较多,基本都是人工操作比较容易出错,也比较琐碎,好心情都被磨没了。
然后我说要么写个小程序吧,帮你处理这些琐碎的工作,然后就大概梳理了一下主要需求:
内部报告:
- 首先需要从系统出导出一个大的 pdf,包含很多小的 pdf
- 每个小的 pdf 报告中包含一些信息,比如 报告标题、姓名、编号、医院、总页数
- 拿到这些信息之后,分割大的 pdf,将小的 pdf 报告剥离处理
- 然后重命名这些报告,格式为
姓名-编号.pdf - 将这些报告移动到对应医院的目录下,然后将这些医院目录压缩
外部报告:
- 外部会发过来压缩包,其中包含单个的 pdf 报告
- 解压缩后将报告拿出来,提取其中的信息,信息基本同内部报告
- 重命名
- 移动到对应的医院目录下,并压缩
实现
人生苦短,我用python。
嗯,python大法好,处理这些琐碎的事情写个 python 脚本跑一下不就好了吗。
python 版本使用的python 3.x。
梳理了下输球,首先需要解析大 pdf 中的一些关键信息,转化为我们需要的报告信息,首先写个Model叫做 Sample,包含 title、number、name、total_page、hospital 等等,然后依次解析 pdf 生成组成 samples 列表,最后根据报告列表分割处理pdf 就好了。
解析 pdf
有个 python 库叫做 pdfminer,这个库已经不支持python 3.x 版本了,该项目注明了可以使用 pdfminer.six来支持3.x的版本。
基本语法如下:
|
|
官网给出的 layout 布局
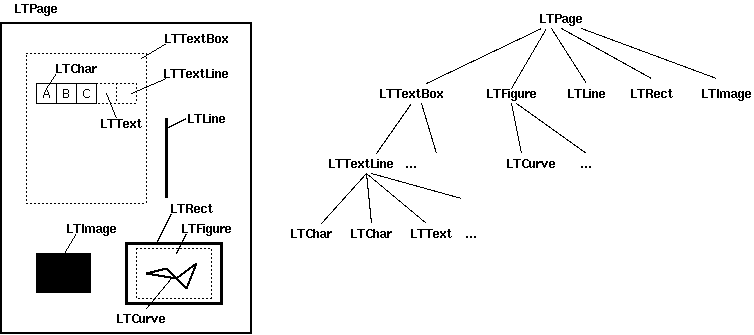
我们主要拿其中的文本信息,所以拿到每一页 pdf 的LTPage后,遍历其中的包含 text 属性的控件就好了,拿到文本信息,根据正则匹配到关心的文本信息,赋值给新建的sample,依次循环,最后组成 samples 报告列表给后面使用。
解析完了后就需要处理 pdf 了。
分割 pdf
首先要做的是将大的 pdf 分割成小的 pdf,搜了下分割 pdf 有个python 库叫做 PyPDF2,参考API 写了一个工具方法用来分割 pdf。
|
|
根据第一步得出的 samples,循环一下拿出其中的total_page,依次分割就好了。
最后就是重命名、移动、压缩,不写了。
打包成 exe 可执行文件
老婆使用的是 Windowns,所以最后要打包成 .exe 可执行文件,搜了下 pyinstaller 可以解决,但是还是需要在对应的平台才能打出对应平台的可执行文件,可就是说想要打出 .exe 必须在 Windows 下打包,这就有点蛋疼了。然后弄了一下,发现 Windows 用来做开发真的是难用无比。
最后也没打 .exe,直接在 Windows 下装了python,双击 .py 文件好了,有bug的话替换一下文件好了,不用重新打包。
碰到的问题
项目交付老婆使用后,极其的好用,大幅提升了工作效率,减少出错概率,老婆甚至发了个朋友圈夸奖了一番,感觉美滋滋。
美了不到两天就出 bug 了。
bug是这样的,比如有个编号编号:G201802020108 正常解析出来 sample.number = G201802020108 才对,但是结果可能是这样的G20180202,后面少了几位。拿到原始的大 pdf 跑了一遍发现确实是这样,每个 pdf 在解析时我都把文本信息存了下来以便查问题用,这时派上了用场,打开看了下文本信息被这样处理了:
|
|
本来在一行或者说在一个 LTTextBox 中的内容被分割成了两个,所以出现了内容少的问题。
找到了问题原因就好处理了。
首先想到了一个方案,每个 LTxx 控件在当页 pdf 中的位置由坐标表示,左上角坐标是 {x0:0,y0:0, x1:0,y1:0},只要框住了编号信息所在的坐标范围,只要在该范围内的,所有文本信息 append 一下然后再正则匹配就好了。
|
|
给定固定坐标范围,找到在该坐标范围内的控件,然后再去匹配。
跑了一下确实生效了,但是问题依然没有解决,为什么呢?因为报告种类不一,导致格式就不一样,坐标范围也不一样,也就是说不能动态的找到坐标范围。该方案失败。
于是又想到了第二个方案,直接看代码吧
|
|
基本解决。
其实第二个方案也不太完美,为什么呢?编号还好说,一般都是字母加数字,如果出现这个bug一般都能比较好判断是否合法,比如编号长度 >=11,但是,如果是名字呢,就没有很好的合法规则来判断,比如名字:张三丰,丰字被分割了,而合法判断是名字长度 >=2,那最后结果就是张三而不是张三丰。
所以,其实还有一个优化方案,在方案一和方案二的基础上,第一步先匹配关键字,比如姓名:,匹配到了以后再框定坐标范围,一般名字都是6字以内,编号是20位以内,划定坐标范围后将范围内的匹配控件文本信息都拿出来再一起解析。基本做到了动态判断坐标范围。
外部报告跟内部报告基本是一样的,区别是首先需要解压一下,然后解析、处理,不写了。
还有哪些可以做
前面写了怎么解析处理pdf,其实还有一部分工作也可以用脚本来处理,比如,大的pdf 下载可以通过脚本处理;处理好的 pdf 报告要通过邮件法发送给客户,也可以通过脚本处理;有时还需要把解析出的信息填到表格中,也是可以用脚本处理的。
总结下来一共有这几个功能:
- 爬虫,从系统中导出大的 pdf 报告
- pdf 解析和分割
- 归类,压缩
- 生成表格
- 发送邮件
目前只做了2 和3 ,其余的有时间慢慢写。
最后
为什么写这篇文章呢?
其实用到的东西很简单,看几分钟 python 入门然后再找两个开源库就搞定了,也没必要记录什么技术知识点。
我真正想说的是一些感悟,程序员碰到这种问题一般都会想办法写一些脚本处理,没什么稀奇的。但是对于不会写程序的人来说,有这个程序和没有这个程序简直就是不一样的工作,就拿这件事来说,用了这个程序之后,我老婆的工作效率明显提升,每天能节省出1-2小时时间做别的事情,从交付那天起,基本没听过老婆再抱怨工作了。简直开心。
还有就是以前总感觉程序员这个工作对生活的帮助简直就是没啥用,比如,你看谁谁现在是医生,去医院都不用挂号,直接就能看病;谁谁是老师,孩子上学的事情根本不用愁等等诸如此类,职业除了能养活自己之外能够反哺生活,在生活中提供一些价值。反观程序员对生活上的帮助简直就是0,甚至可以说是负数。
现在是高速发展的信息时代,干什么工作都离不开手机、电脑,甚至人工智能在某些方面都开始取代人力去做一些工作,所以我觉得越来越能体现出程序员的价值,可以控制机器取代人工去做一些重复性的、机械性的工作,所以在有能力的前提下学习一些开发知识会大有裨益。就像每个人都学英语一样,在未来,编程也有可能是一门基础学科,每个人都应该掌握。
回到现在,简单的用一些简单的脚本提升生活幸福感,把这些烦人的工作交给机器去做,人类最擅长的是浪费时间,恩。


本文链接: http://w4lle.com/2018/02/02/python-pdf/
版权声明:本文为 w4lle 原创文章,可以随意转载,但必须在明确位置注明出处!
本文链接: http://w4lle.com/2018/02/02/python-pdf/