UI2Code(一)pix2code
pix2code 项目通过机器学习,支持输入一张图片输出实际的布局代码,同时支持生成三端(Android、iOS、web)布局代码。
pix2code作为UI2Code的先驱项目,后续的相关项目或多或少的都有参考该项目的实现。
系列文章:
概述
使用双显卡服务器跑出模型,耗时大概1.5小时,模型数量1500张图片,1500个对应DSL,模型大小450M左右
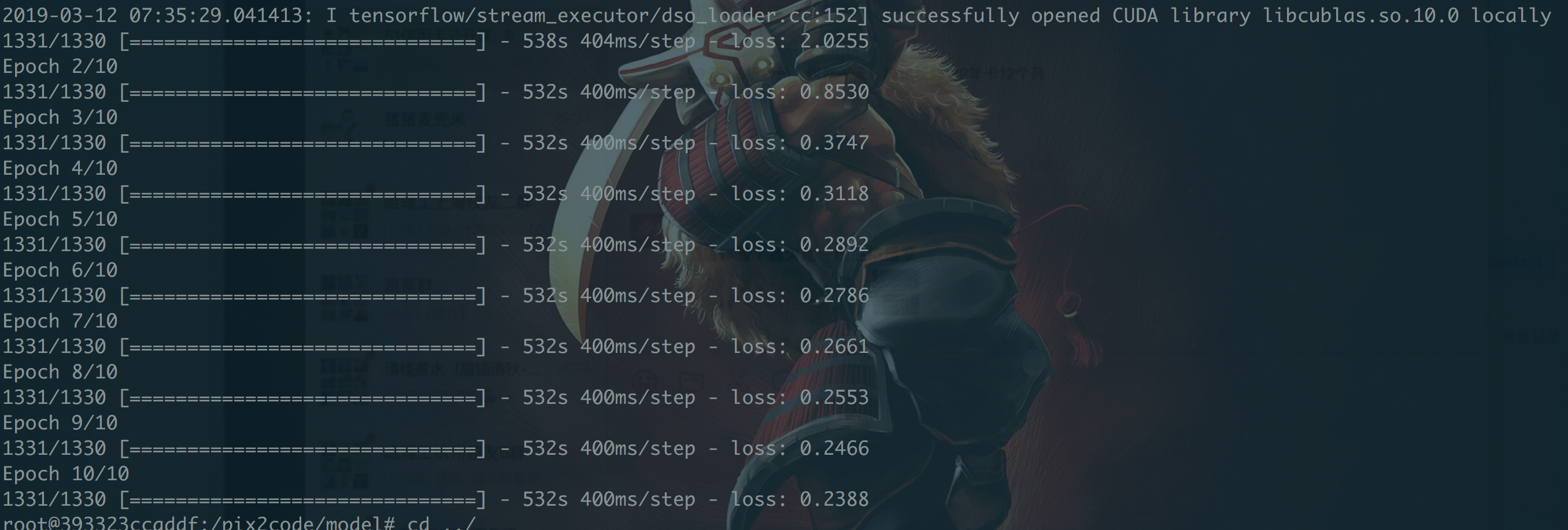
然后使用验证集生成DSL,比对原始DSL
对比1:
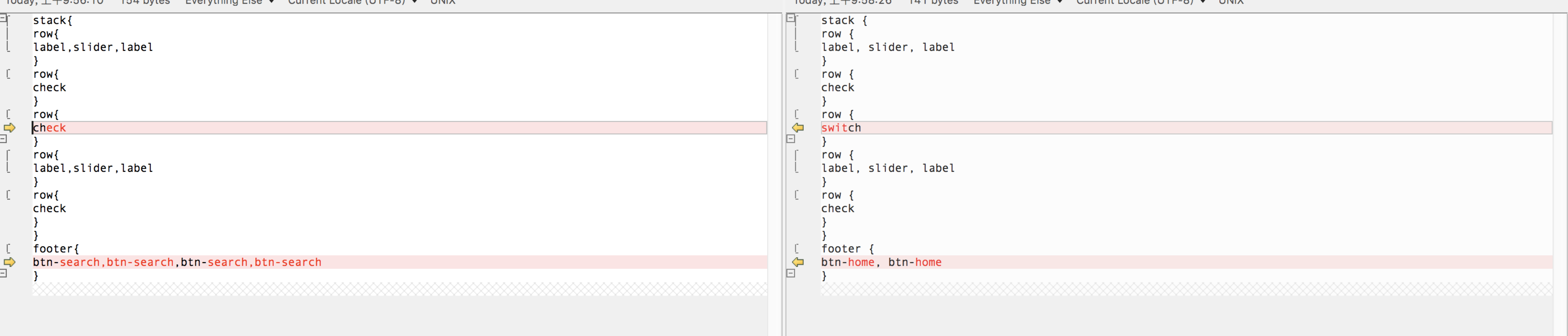
对比2:

对比3:
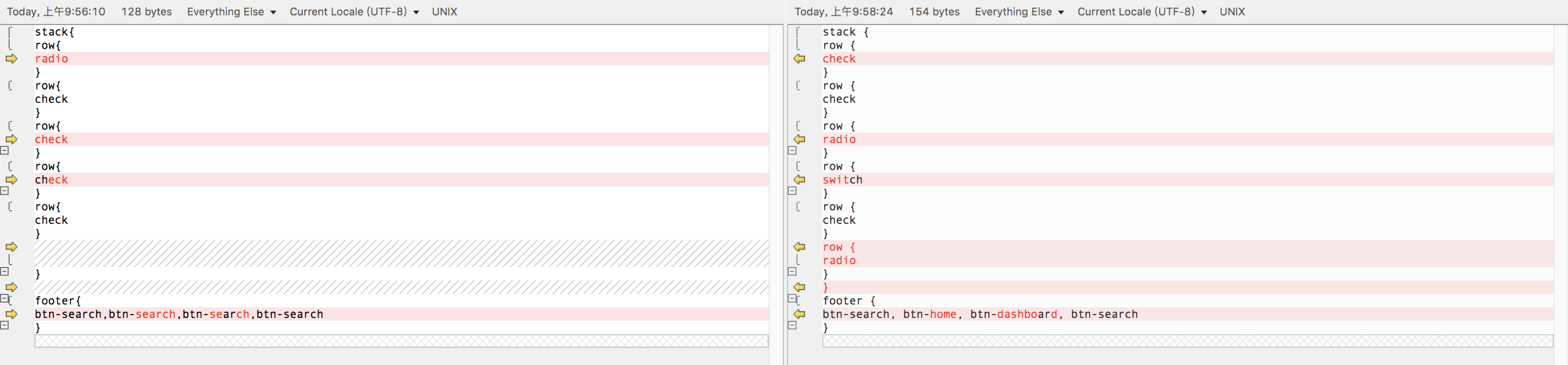
验证集共生成了250张图片对应的DSL,总体来看不能做到100%还原DSL,作者称可以做到77%左右的准确率。
以其中一个图片为例
生成的DSL
|
|
编译compile后生成的Android xml 布局文件
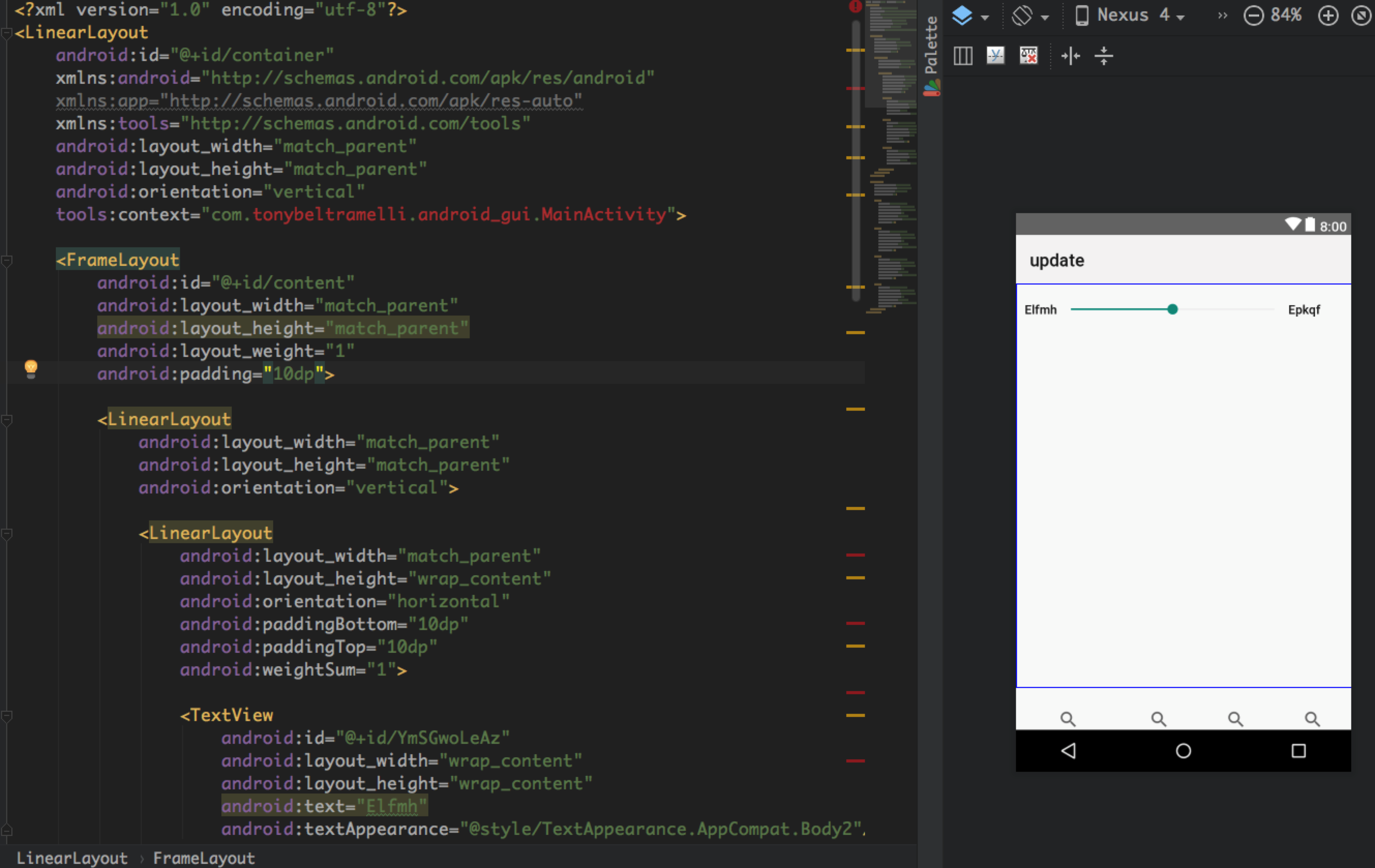
结果是有10个控件,其中的8个是正确的,2个是识别错误的。
实现原理
基于图像标记(image caption)构建一种把图像和文本连接在一起的模型,用于生成源图像内容的描述。
pix2code是一个基于卷及神经网络(CNN)和循环神经网络(LSTM,长短时神经单元)能够由单个GUI屏幕截图生成源代码的项目。
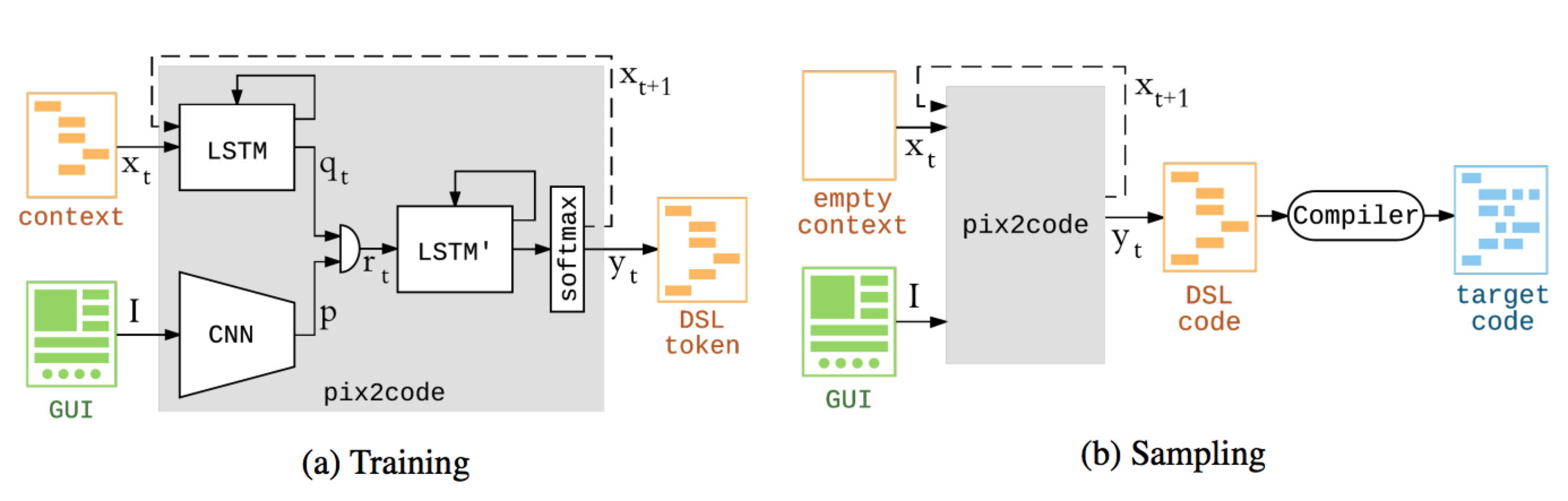
模型采用监督学习,有连个输入,一个数GUI截图,另外一个是对应的布局DSL。这些布局文件都足够简单,DSL也仅仅对控件进行了描述,不涉及位置信息和控件属性。
首先将GUI图像 I 通过CNN网络生成特征向量P,然后DSL 符号T 描述切割成一个序列 X(xt, t ∈ {0 . . . T − 1})通过第一个语言模型得到特征向量qt(该语言模型由两个 LSTM 层、每层带有128个神经单元来实现),视觉编码向量 p 和语言编码向量 qt 可以级联为单一向量 rt,该级联向量 rt 随后可以投送到基于 LSTM 的模型来解码。因此解码器就学到了输入 GUI 图像中的对象和 DSL 代码中的符号间的关系,因此也就可以对这一关系进行建模。我们的解码器由两个 LSTM 层、每层带有 512 个单元的堆栈而实现。最后通过一个softmax进行一个分类对当前项进行预测,并把结果作为下一项的输入。
核心代码:
|
|
具体原理参考论文翻译。
生成 DSL 后,通过compiler编译成三端代码 UI -> DSL -> Code。
其中compile过程,就是替换DSL描述到实际控件的过程,这些实际控件的属性和布局位置信息全是写死的,存在放dsl-mapping文件中,以其中一个控件为例,对照关系如下:
|
|
所以pix2code的核心是通过机器学习得到对应布局的DSL,compiler 是规则替换的过程。
优化
pix2code具有70%左右的准确率, 基于该项目,西安交大通过一些优化使准确率进一步提高。
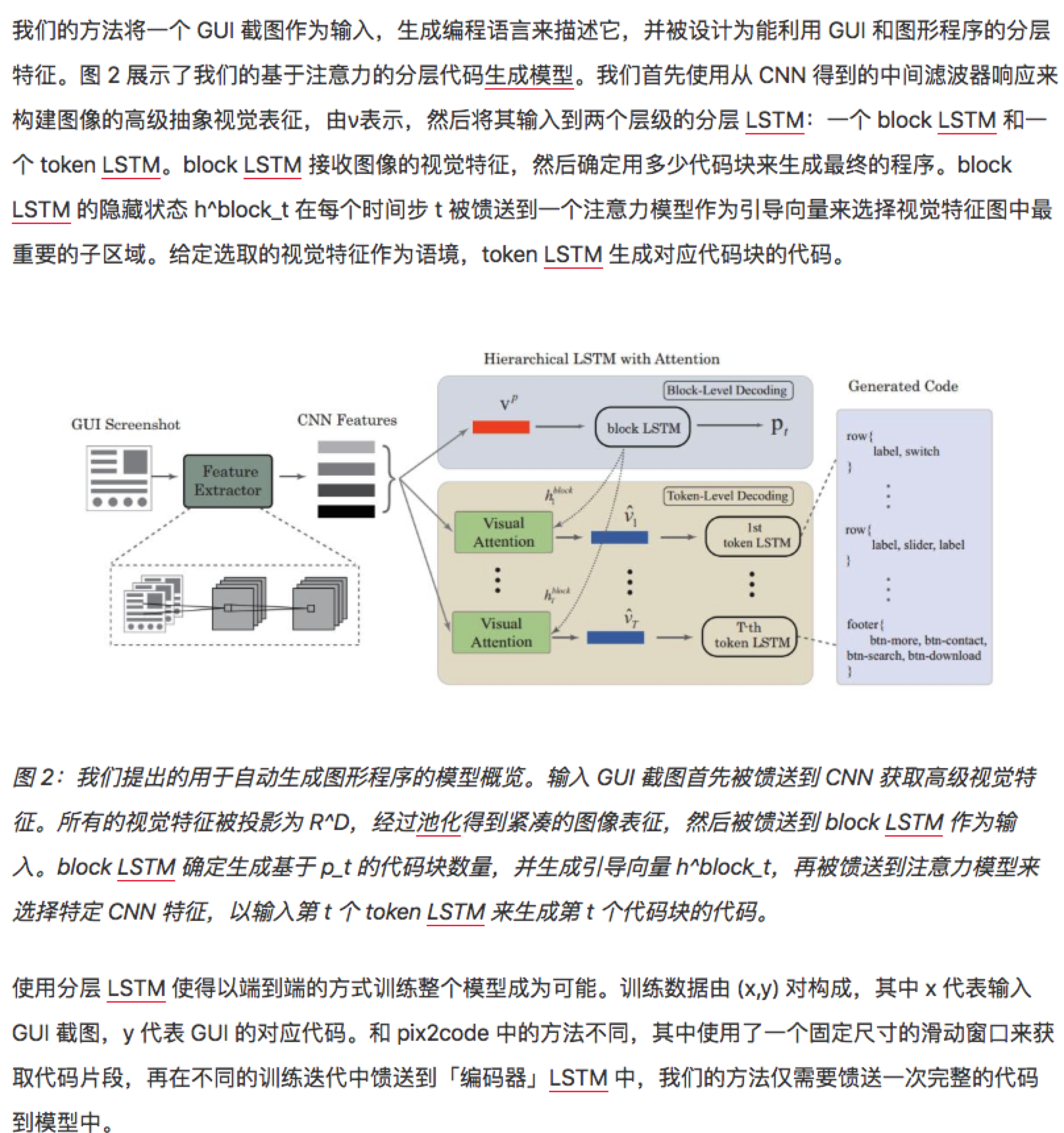
参考文章 https://www.jiqizhixin.com/articles/2018-11-05-12?from=synced&keyword=pix2Code
总结
pix2code项目本身作为一个实验性质的项目,论证了GUI截图通过AI手段自动生成布局代码的可行性。
但是由于其也存在一些问题:
- 模型准确率不高,修改模型或者重新构建模型成本高
- 中间过程不允许人工干预,其结果就是完整的DSL,人工干预是在DSL生成后
- 训练素材标准成本高,这也是深度学习都会碰到的一个实际问题
- 切割精准度不够,实际上它是以CNN网络提取图片特征,精准度不大达到像素级别的要求
- 控件位置和属性信息缺失,不能准确还原布局
基于以上调研分析,pix2code项目仅仅作为一个研究性项目进行开源,并不能实际使用在生产环境中,作者明确表述该项目和论文仅仅作为实验,并且不会再进行进一步的平台拓展。
我们可以探索在pix2code基础上,通过图像分析+pix2code控件识别 来进行UI2Code的工作。
后面会去调研下pixelToApp这个项目,其基于传统的计算机视觉识别技术进行代码生成。
论文:
参考文章:
- 深度学习助力前端开发:自动生成GUI图代码
- 基于AI的移动端自动化测试框架的设计
- 前端设计图转代码,西安交大表示复杂界面也能一步步搞定
- 前端利器!让AI根据手绘原型生成HTML | 教程+代码
- How you can train an AI to convert your design mockups into HTML and CSS
本文链接: http://w4lle.com/2019/03/13/UI2Code-0/
版权声明:本文为 w4lle 原创文章,可以随意转载,但必须在明确位置注明出处!
本文链接: http://w4lle.com/2019/03/13/UI2Code-0/